

Obiettivi e aspettative educative di Ottimo in questa lezione sui Big Data:
Dai cari amici di Ottimo ci si aspetta che dopo aver studiato questa lezione saranno in grado di:
- Spiegare brevemente che cosa sono i big data.
- Descrivere i modelli 3V e 4V nella definizione dei big data.
- Elencare alcuni esempi di applicazioni per big data.
Big Data è uno dei termini più frequenti nelle professioni e negli scritti legati alla tecnologia dell’informazione.
Se effettui una ricerca su Google per “applicazioni di big data”, scoprirai che esistono le applicazioni di big data in medicina, economia, banche, così come per contabilità e revisione contabile.

Sono solo una piccola parte delle domande e delle preoccupazioni di coloro che sono interessati a questo campo.
In una certa misura, quando sentiamo parlare di big data tutti possiamo indovinarne il significato: sembra che, in termini semplici, si possa dire che la questione dei big data è correlata a una grande quantità di dati: il volume aumenta ogni giorno e ognuno di noi, a qualsiasi livello di attività, ne ha visti e gli effetti e li ha sperimentati.
Ma per una definizione più accurata, andiamo al Gartner Institute e leggiamo la definizione di Gartner dei Big Data:
Definizione di Gartner
Big Data indica risorse di informazioni [una raccolta o un’organizzazione] che:
- Hanno un volume elevato.
- Sono prodotte rapidamente e/o hanno un’ampia varietà.
- Hanno bisogno di metodi di elaborazione innovativi ed economici che possano essere utilizzati per automatizzare i processi, prendere decisioni e migliorare l’intuizione.
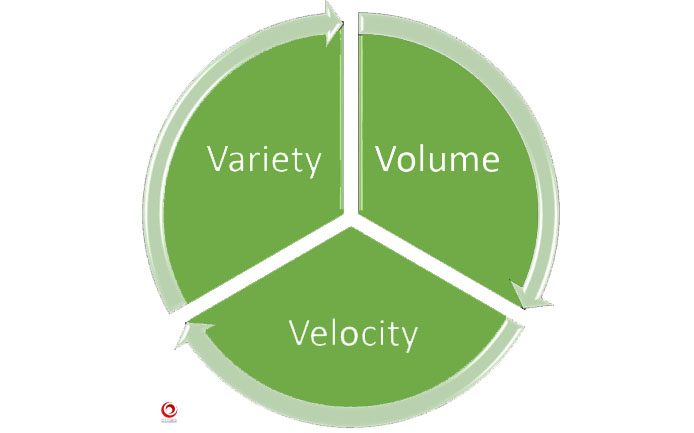
Modello Big Data 3V
Nella maggior parte delle definizioni di big data, sono presenti i tre termini Volume, Velocità e Varietà. Per questo il termine 3V viene talvolta utilizzato per definire i big data.
Ad esempio, PWC, una delle società di consulenza manageriale leader a livello mondiale, definisce i big data proprio con 3V. (File PDF)
La maggior parte degli articoli nel manuale dell’applicazione dei Big Data si basa sulla definizione di 3V. (Link)
Nel suo libro Customer Relationship Management, Francis Butel segue il modello 3V quando si tratta di CRM analitico.
La Ernst & Young Company nella sua guida ai big data (Big-data-applications-and-insights) menziona anche questa definizione. Ma inserisce una quarta V per aggiungere qualcosa di nuovo (la quarta V è la prima lettera di Veracity ed è importante perché si riferisce all’accuratezza e affidabilità dei dati).
Come regola generale, devi sapere che il modello 3V (o 4V) è un modello comune e ben noto per la definizione dei big data e ora possiamo passare a una definizione più precisa di ciascuna di queste componenti.
Forse non c’è fonte migliore per questo di un vecchio articolo (2001) in cui si menzionano queste parole per la prima volta:
L’articolo, che è la fonte della definizione 3V, porta la firma di Douglas Laney. All’epoca lavorava con il Meta Group, che nel 2005 è stato acquistato dal Gartner Institute e ha continuato a operare come filiale di questo grande gigante del management.
Il titolo dell’articolo era: 3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety
Non dovresti dimenticare la data di scrittura dell’articolo. A quel tempo, la questione dei grandi volumi di dati non era così seria come lo è oggi, e persino l’e-commerce era agli inizi.
Ricorda solo che Google aveva tre anni in quel momento e Amazon aveva circa sette anni.
Gestione dei dati 3D
Leggiamo questa parte della lezione con la stessa visione di Douglas Lenny. L’autore ha esaminato quattro fattori determinanti per il futuro dei dati:
- La crescente ondata di e-commerce.
- L’aumento dell’integrazione aziendale e delle attività di acquisizione tra le aziende.
- L’aumento dell’interazione tra i reparti di un’azienda e tra diverse attività.
- Le aziende stanno cercando di utilizzare le informazioni come catalizzatore competitivo.
Il punto sottolineato in questo articolo è legato alle implicazioni per la crescita dell’e-commerce.
Volume dei dati
Con l’aumento dell’utilizzo della tecnologia da parte delle attività aziendali, la quantità di dati generati in ogni transazione è cresciuta.
Ad esempio, nella fatturazione tradizionale, non si hanno le ore, i minuti e i secondi di fatturazione, ma nelle transazioni digitali queste informazioni esistono e il sistema registra.
Oppure nelle transazioni digitali (in particolare nelle transazioni finanziarie), l’indirizzo IP e l’indirizzo e-mail vengono solitamente registrati.
Inoltre, i file che alleghi a un modulo online sono nuovi dati che vengono registrati e archiviati in interazioni (la possibilità di trasferimento e duplicazione gratuiti ed economici aumenta il desiderio di utilizzare informazioni aggiuntive).
Velocità di generazione dei dati (Velocity)
Naturalmente, qui avrebbe avuto più senso che Lenny usasse il termine Velocità di generazione dei dati o qualcosa del genere. Ma ha scelto Velocity per far iniziare tutte e tre le parole con la lettera V.
Tuttavia, la conclusione è questa: l’infrastruttura elettronica accelera le transazioni. Il numero di fatture emesse in un terminale di pagamento di un sito web può – potenzialmente – essere molto più alto del numero di fatture emesse dalla cassa di un negozio o dalla cassa di una banca.
Il numero di registrazioni effettuate su un sito web può anche essere molto superiore al numero di moduli di registrazione cartacei compilati in una mostra o in una sede aziendale.
In sostanza, se nell’e-commerce la velocità delle interazioni e delle transazioni non è più veloce dell’interazione fisica, le imprese digitali perdono uno dei loro potenziali vantaggi competitivi.
Accelerare il tempo di ogni attività e aumentare il numero di attività per unità di tempo significa anche aumentare il volume dei dati generati.
Varietà
Il concetto di diversità è uno dei concetti chiave dei Big Data. In effetti, le sfide serie iniziano quando i tuoi dati sono diversi.
Supponiamo di avere informazioni su diverse centinaia di migliaia di fatture emesse in un negozio in due o tre anni. Queste informazioni possono essere considerate ingombranti.
Ma quando metti insieme le informazioni sulle fatture emesse in un centro commerciale, il problema si complica. Perché le merci registrate nelle fatture saranno di molti generi.
Considera ora che molti clienti, per entrare a far parte del customer club dei centri commerciali, ti hanno informato anche della loro data di nascita.
Aggiungete a ciò il fatto che oltre ai referral fisici, i clienti possono anche fare una parte del loro ordine online. Quindi in alcuni acquisti si hanno anche informazioni come la versione del browser del cliente, l’uso del cellulare o del desktop e la banca preferita dal cliente.
Cosa si può fare con questa quantità di dati? Dovremmo tenerli tutti? Oppure alcuni di essi sono inutili ed è meglio non sostenere il costo e il fastidio di conservarli e di archiviarli?
Per complicare le cose, supponiamo che i gestori del centro commerciale stiano allestendo un altro centro commerciale in città e vogliano integrare le due infrastrutture informatiche. In quel centro commerciale, le informazioni venivano ricevute e registrate dai clienti. Ma la definizione dei dati, la varietà dei dati e il modo in cui vengono registrati sono diversi dalla creazione di un database corrente.
Questi sono solo alcuni degli shareware per la definizione degli obiettivi che puoi utilizzare.
Nuove sfide nella gestione dei dati
Tutte le questioni che Douglas Lenny ha sollevato nel 2001 sono ancora attuali. Ma lo sviluppo della tecnologia ha aggiunto nuove dimensioni alla loro complessità.
Basti pensare alla popolarità dei social network e delle piattaforme social. Pensa al software di messaggistica che tutti usiamo ogni giorno.
Anche la quota crescente di transazioni digitali sul totale delle transazioni finanziarie è una tendenza abbastanza visibile e tangibile in tutto il mondo.
La diffusione dell’Internet of Things può anche aumentare il volume, la velocità e la varietà della produzione di dati. Immagina solo che la posizione approssimativa di molti dei nostri telefoni cellulari può essere consultata e registrata dagli operatori e da molte delle applicazioni cui abbiamo dato l’autorizzazione.
Forse un decennio fa, la domanda era come ottenere maggiori informazioni dai nostri clienti, dal pubblico o dagli utenti. La sfida seria ora è: cosa fare con questa quantità di informazioni che si possono ottenere?
Nel seguito di questa lezione, menzioneremo alcune di queste sfide.
Sfide operative e analitiche nel dibattito sui big data
Alcune delle sfide dei big data sono analitiche:
- Come trattare questi dati?
- Quanto è utile ogni dato che possiamo ottenere?
- Quali dati non vale la pena raccogliere?
- Qual è il rapporto tra il profitto derivante dall’acquisizione, l’archiviazione e l’analisi di un dato e il costo per farlo? La raccolta e l’analisi dei dati è economicamente giustificata?
- Quali decisioni prende la nostra azienda che l’analisi dei big data può aiutare a migliorare?
Alcune delle sfide dei big data sono anche operative:
- Quali modifiche dovremmo apportare ai nostri processi aziendali per ottenere dati più utili?
- Dove e come archiviare i dati? In modo centralizzato o distribuito?
- Di quali dati abbiamo meno bisogno? Memorizzare nella cache alcuni dei dati non rischia di mettere a dura prova i nostri sistemi?
- Quali dati dovremmo archiviare sui dispositivi delle persone (cellulare, laptop, smart TV, smartwatch, Chromecast, ecc.)? E quali sui nostri server?
- Dobbiamo ottenere tutti i dati grezzi ed elaborarli noi stessi? Oppure una parte dell’elaborazione può essere affidata al cliente e all’utente in modo che, ad esempio, il suo telefono cellulare o laptop o smartwatch possa semplicemente inviarci il risultato dell’elaborazione?
Inoltre, dovresti aggiungere gli aspetti legali e le restrizioni sulla privacy alla discussione sui Big Data. Negli ultimi anni abbiamo visto numerosi esempi di disattenzione su questi punti, di cui lo scandalo che ha coinvolto Facebook nella vicenda Cambridge Analytica è solo un esempio.
Quali sono le maggiori applicazioni dei big data?
Quando parliamo di big data, parliamo soprattutto di una situazione, una situazione in cui vengono generati grandi volumi di dati ad alta velocità e ad ampia varietà.
Ma la gestione di una situazione del genere richiede altre conoscenze. Data scientist, specialisti di intelligenza artificiale ed esperti di data mining sono tra coloro che possono trovare e sviluppare applicazioni di Big Data in una varietà di campi.
Il termine Big Data Applications è comune e lo usiamo in italiano e inglese. Tieni sempre presente che si riferisce ad applicazioni in grado di analizzare il big data. Se il volume e la varietà dei dati non sono utili di per sé e se non viene eseguita la corretta analisi ed elaborazione dei dati di massa, questi dati non saranno diversi dalle altre risorse inutili.
In genere, affrontare i dettagli di queste applicazioni è una discussione specializzata e va oltre l’ambito del nostro corso di alfabetizzazione digitale. Ma forse i seguenti punti possono essere un suggerimento per ulteriori ricerche e per studi più completi.
A cosa servono i Big Data? Dai un’occhiata ad alcuni semplici esempi
Le applicazioni dei big data nella vita di tutti i giorni includono servizi di routing come Waze e la sezione Navigazione di Google Maps. Quantità significative di dati relativi ai veicoli in movimento (in realtà: telefoni cellulari) vengono elaborati in modo continuo e istantaneo e in questo modo vengono determinati i percorsi più appropriati in base alla destinazione e vengono suggeriti agli utenti.
In termini di gestione delle relazioni con i clienti, il CRM analitico è una delle aree in cui l’uso dei big data è ben noto e il ripasso del corso CRM analitico può dartene un’idea.
Se hai familiarità con la segmentazione del mercato e l’analisi del comportamento dei clienti, puoi senza dubbio immaginare quanto possa essere utile l’analisi dei Big Data per aiutare i decisori in quest’area.
Se hai familiarità con l’argomento della personalizzazione, puoi intuire come l’analisi dei dati ad alto volume può aiutarti a pianificare la personalizzazione dei servizi.
Naturalmente, la personalizzazione dei servizi è possibile anche senza l’analisi dei big data. Ma quando hai molte opzioni e risorse limitate, è naturale che la personalizzazione basata sull’analisi dei Big Data possa aiutare a valutare le opzioni più efficaci (rispetto al costo di ciascuna opzione) per te.
Anche le imprese digitali utilizzano i sistemi di raccomandazione e l’uso dei Big Data in questo campo ha prodotto risultati tangibili.
Nella medicina
Una delle aree da sempre prese in considerazione nel dibattito sui Big Data è la medicina. Ci sono diverse ragioni per questo:
- Informazioni numeriche ampie e varie che possono essere ottenute dai pazienti (rispetto ai domini qualitativi).
- Desiderio umano di cooperare nel campo della salute (ognuno suppone di poterne avere dei benefici per sé).
- Le tante applicazioni e i tanti strumenti che oggi vengono utilizzati nel campo della salute e la grande mole di dati che producono (ti basti pensare al sensore accelerometro del tuo smartphone che registra i tuoi movimenti per gran parte della giornata).
Ma nell’esaminare l’uso dei big data in medicina, è importante distinguere tra diverse aree. Ad esempio, il campo delle previsioni è una delle aree in cui c’è relativamente più speranza e ha compiuto progressi interessanti (potresti conoscere il progetto Google Flu, che mirava a prevedere le statistiche e l’andamento dei focolai di influenza in luoghi diversi, in base alla ricerca degli utenti).
La categoria diagnostica è la seconda area che è cresciuta in modo significativo e si prevede che la capacità di elaborare grandi volumi di immagini dei pazienti creerà preziose opportunità per le diagnosi in futuro.
Il campo del trattamento e delle decisioni correlate è il ramo più difficile e dovremo aspettare molto tempo per vedere e sperimentare i suoi risultati tangibili.
Per approfondire
Se sei interessato a saperne di più sull’applicazione dei big data in medicina e sulla salute in generale, i seguenti due articoli possono essere un buon punto di partenza:
Big-Data-Revolution-in-Healthcare
Big-data-analytics-in-healthcare
Il primo è stato scritto da McKinsey ed è un po’ più generale. Il secondo è più utile per via delle risorse che introduce. La maggior parte dei riferimenti presentati sono utili, informativi e semplici. Ovviamente, è naturale che abbiamo preso questi due testi pensando al pubblico dei principianti e se vuoi studiare professionalmente in questo campo dovresti andare su riviste specializzate.
SEO
La SEO è un’altra area in cui abbiamo utilizzato ampiamente l’analisi dei Big Data e tutti ne abbiamo sperimentato i risultati.
Nella storia della SEO, abbiamo sottolineato che andare oltre il semplice affidamento sull’analisi delle parole chiave e sugli algoritmi di analisi comportamentale ha reso i metodi SEO black hat non più efficaci. Una parte importante di questo risultato dovrebbe essere attribuita alla capacità di analizzare il comportamento degli utenti su larga scala.
Oggigiorno, se i siti possono utilizzare tecniche come il SEO black hat per ottenere un posto nelle prime posizioni dei risultati di ricerca, i motori di ricerca (in particolare Google) rapidamente, dopo aver inviato i visitatori a queste pagine e aver esaminato il loro comportamento, vedranno la bassa qualità di queste pagine. E correggeranno i loro risultati per le successive ricerche eseguite dagli utenti.
Naturalmente, l’uso dei big data in vari campi va ben oltre i casi limitati qui menzionati, e in ogni caso sono stati scritti e pubblicati anche libri specializzati.
Ma, in generale, devi tenere presente che i Big Data sono ancora molto giovani e c’è ancora molta strada da fare prima di poter vedere e sperimentare le sue applicazioni commerciali e diffuse nel corso della nostra vita.
Cosa devo fare dopo aver letto questa lezione?
Puoi leggere l’introduzione al libro Everyone Lies. Questo libro può essere utile per coloro che non hanno familiarità con i big data e le applicazioni per big data.




